Интерактивный тренажёр по robots.txt
Материал не ориентирован на аудиторию SEO-гуру
, основатель и владелец SEO-компании Distilled")
Вводный инструктаж
Robots.txt – это простой текстовый файл, располагающийся в корневом каталоге домена (www.example.com/robots.txt). Являясь общепризнанным стандартом, он позволяет вебмастерам регулировать все виды автоматического использования сайта – в частности, ограничивать доступ поисковым роботам к содержимому сайта (запрещать сканирование и индексирование).
Каждый из уроков интерактивного учебника по robots.txt завершается практическим заданием. Чтобы проэкзаменовать себя, исправляйте строки команд в полях в соответствии с инструкциями. Если введённый Вами ответ окажется правильным, поле окрасится в зелёный цвет.
Урок 1. Базовое исключение
Теоретическая часть:
Наиболее распространённый сценарий использования robots.txt – это блокировка доступа роботам к определённым страницам. Самый простой вариант – применение правила для всех роботов (агентов пользователя), прописываемое в виде строки User-agent: *. Все последующие за ней строки содержат предписания на запрет сканирования и индексирования конкретных страниц, файлов, каталогов – они начинаются с Disallow: /. Так, например, нижеприведённый код блокирует роботам доступ к /secret.html.
Практическое задание:
Внесите ещё одно предписание, чтобы заблокировать доступ к /secret2.html в дополнение к /secret.html.
Урок 2: Исключение каталогов
Теоретическая часть:
Если вы заканчиваете предписание на закрытие от поисковых роботов косым слэшем ("/"), например, так: Disallow: /private/, будет заблокировано всё содержимое данного каталога.
Практическое задание:
Измените правила исключения в нижеприведённой строке, чтобы заблокировать папку под названием secret, вместо страницы secret.html.
Урок 3: Разрешение отдельных траекторий
Теоретическая часть:
В дополнение к запрету доступа к конкретным траекториям (ссылкам) синтаксис robots.txt позволяет открывать доступ к отдельным файлам, страницам, каталогам. Необходимо отметить, что доступ поисковым роботам открыт по умолчанию, так что, если в файле нет никаких указаний от вебмастера, все пути для googlebot и его коллег открыты.
Основное применение директивы Allow: – это исключение отдельных страниц/элементов из общего предписания по Disallow:. Закон приоритетного правила гласит:
Наиболее конкретное правило, определяющееся по длине записи [пути], будет превалировать над менее конкретным (более коротким) правилом. Порядок приоритетности предписаний с шаблонами не определён.
Практическое задание:
Подкорректируйте исключение папки /secret/ внизу, разрешив роботам с помощью правила Allow: доступ к /secret/not-secret.html. Поскольку это правило длиннее, ему будет придаваться первостепенное значение.
Урок 4: Ограничения для отдельных Агентов пользователя
Теоретическая часть:
Каждая из вышерассмотренных директив одинаково распространялась на всех роботов. Такое предписание было заложено в строке User-agent: *, с которой начиналась каждая команда. Заменив * на название конкретного робота, можно создавать правила, касающиеся исключительно его одного.
Практическое задание:
Замените * на googlebot в нижеприведённом примере, чтобы запретить доступ к папке /secret/ одному только роботу Google и открыть для роботов остальных ПС.
Урок 5: Добавление множественной блокировки
Теоретическая часть:
Можно создавать сразу несколько блоков команд, ориентированных на различные группы роботов. Нижеприведённый пример robots.txt разрешает доступ googlebot ко всем файлам, за исключением тех, которые включены в каталог /secret/, и запрещает всем остальным роботам доступ к сайту в целом. Поскольку имеется набор директив, направленных конкретно на googlebot, googlebot полностью будет игнорировать команды, распространяющиеся на всех роботов сразу. Это свидетельствует о невозможности создания персональных исключений на базе общих предписаний. Если Вы хотите задать правила для отдельно взятых роботов, следует создавать отдельные предписания для каждого из них поимённо.
Практическое задание:
Добавьте второй блок директив, направленный на всех роботов (User-agent: *), который блокирует весь сайт (Disallow: /). Это позволит создать файл robots.txt, который запрещает доступ ко всему сайту всем веб-паукам, за исключением googlebot. Он, согласно первому – персональному – предписанию, может сканировать все страницы, кроме тех, что в папке /secret/. (Каждую директиву прописываем с новой строки!)
Урок 6: Использование более конкретных User Agents
Теоретическая часть:
Бывают случаи, когда необходимо контролировать поведение отдельных краулеров, таких как паук Google-картинок, отдельно от основного робота Google. Для того чтобы реализовать это в robots.txt, приходится прописывать для каждого из краулеров (как для отдельного User-agent) прямые предписания. К примеру, если при наличии блока инструкций для googlebot есть отдельный для googlebot-images, картиночный паук будет руководствоваться последним. Если же нет персональных указаний для googlebot-images (или других специальных роботов Google), этот краулер будет подчиняться общим директивам для googlebot.
Практическое задание:
В нижеследующем примере robots.txt googlebot-images будет подчиняться директивам для googlebot (т.е. не будет сканировать папку /secret/). Измените предписание так, чтобы инструкции для googlebot (и googlebot-news и т.д.) остались теми же, а для googlebot-images появилось отдельное предписание, запрещающее доступ к папкам /secret/ и /copyright/. (Каждую директиву прописываем с новой строки!)
Урок 7: Основные шаблоны
Теоретическая часть:
Завершающие строку шаблоны (обозначенные *) игнорируются: Disallow: /private* считывается так же, как и Disallow: /private. Тем не менее, такие шаблоны эффективны для работы с несколькими видами страниц одновременно. Символ звёздочка (*) обозначает любую (в том числе пустую) последовательность любых валидных символов (включая /, ? и т.д.).
К примеру, Disallow: news*.html блокирует:
- news.html
- news1.html
- news1234.html
- newsy.html
- news1234.html?id=1
Однако оставляет доступным:
- newshtml из-за отсутствия «.»
- News.html из-за чувствительности к регистру
- /directory/news.html
Практическое задание:
Исправьте нижеприведённую схему, чтобы заблокировать в директории blog только те страницы, которые заканчиваются на .html, вместо блокировки каталога целиком.
Урок 8: Блокировка конкретных параметров
Теоретическая часть:
В числе распространённых вариантов использования шаблонов находится и блокировка конкретных параметров. Например, один из способов обработки фасетной навигации – это блокировка комбинаций из 4-х и более фасетов (параметров). К примеру, можно добавить в своей системе такой параметр для всех комбинаций из 4+ фасетов как ?crawl=no. Это будет означать, к примеру, что URL для 3-х параметров может быть /facet1/facet2/facet3/, но, когда добавится 4-ый, он превратится в /facet1/facet2/facet3/facet4/?crawl=no.
Правило блокировки для роботов в данном случае должно выглядеть как *crawl=no (не *?crawl=no).
Практическое задание:
Добавьте правило Disallow: в robots.txt внизу, чтобы предотвратить сканирование всех страниц, которые содержат crawl=no.
Урок 9: Работа с целыми именами файлов
Теоретическая часть:
Пример исключения папок, в котором модели /private/ будут соответствовать траектории всех файлов, принадлежащих этой папке (в частности, /private/privatefile.html), показал, что по умолчанию образцы, указанные в robots.txt, соответствуют лишь части имени файла и не позволяют ничему идти после второго слэша, даже без специально заданных шаблонов.
Бывают случаи, когда необходимо закрыть от сканирования и индексации отдельные имена файлов целиком (с шаблонами или без них). Например, следующий образец robots.txt выглядит как предотвращение сканирования jpg-файлов, но на самом деле также предотвращает сканирование файла под именем explanation-of-.jpg.html, так как он тоже соответствует шаблону.
Если Вам нужен шаблон, задающий соответствие конечных символов URL-адреса (имени файла), заканчивайте командную строку знаком $. К примеру, изменение исключения с Disallow: /private.html на Disallow: /private.html$ нарушит шаблонное соответствие /private.html?sort=asc и, следовательно, позволит сканировать эту страницу.
Практическое задание:
Измените нижеприведённый шаблон, чтобы исключить действующие .jpg-файлы (т.е. те, которые заканчиваются .jpg).
Урок 10: Добавление XML Карты сайта
Теоретическая часть:
Последняя строка многих файлов robots.txt является директивой, указывающей местоположение XML Карты сайта. Существует множество причин для включения Sitemap для вашего сайта, а также для включения её в Ваш файл robots.txt. Указать местоположение вашей sitemap можно с помощью директивы Sitemap: <ссылка>.
Практическое задание:
Добавьте директиву Sitemap в нижеприведённый robots.txt для карты сайта под названием my-sitemap.xml, которую можно найти по адресу http://www.distilled.net/my-sitemap.xml.
Урок 11: Добавление Sitemap для Видео
Теоретическая часть:
На самом деле Вы можете добавить несколько XML Карт сайта (каждую отдельной строкой), используя тот же синтаксис.
Практическое задание:
Измените нижеприведённый robots.txt, чтобы включить в него video sitemap под названием my-video-sitemap.xml, располагающуюся в /my-video-sitemap.xml.
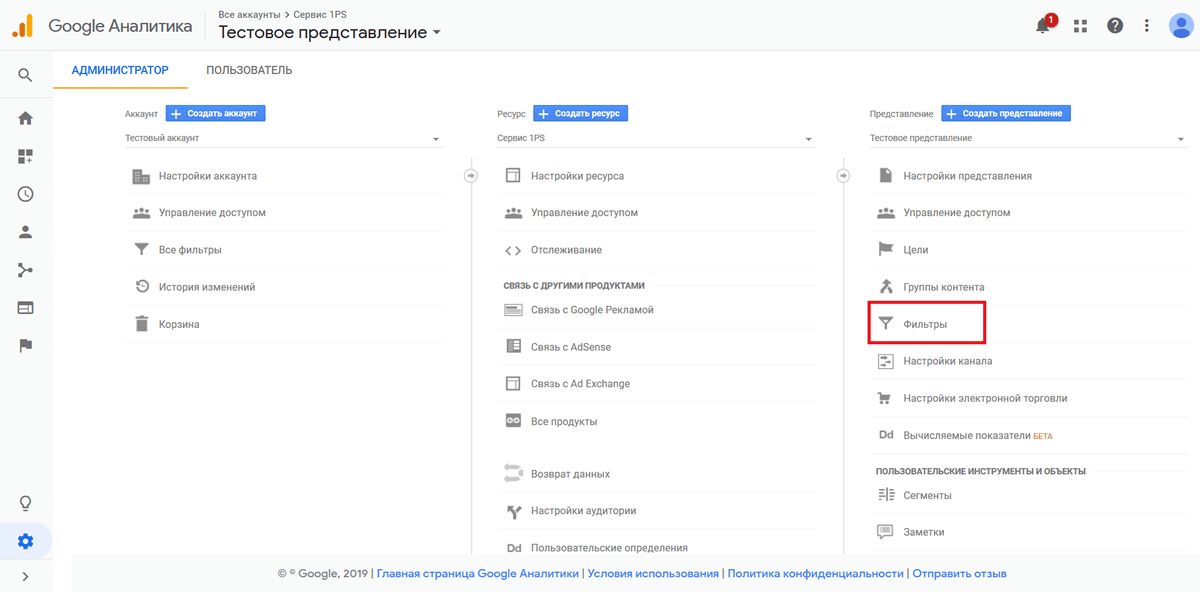
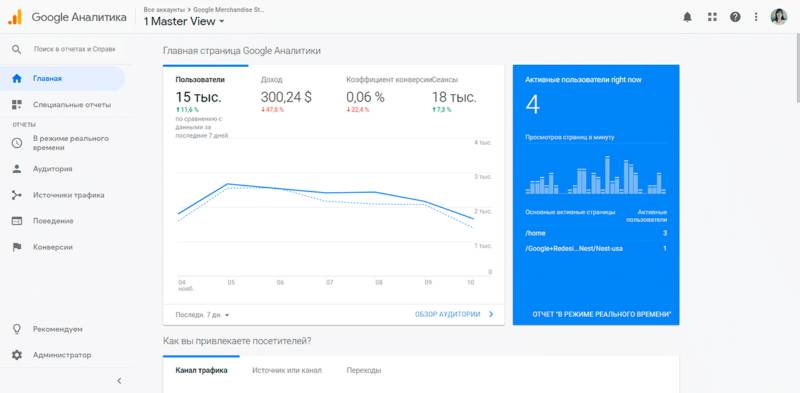

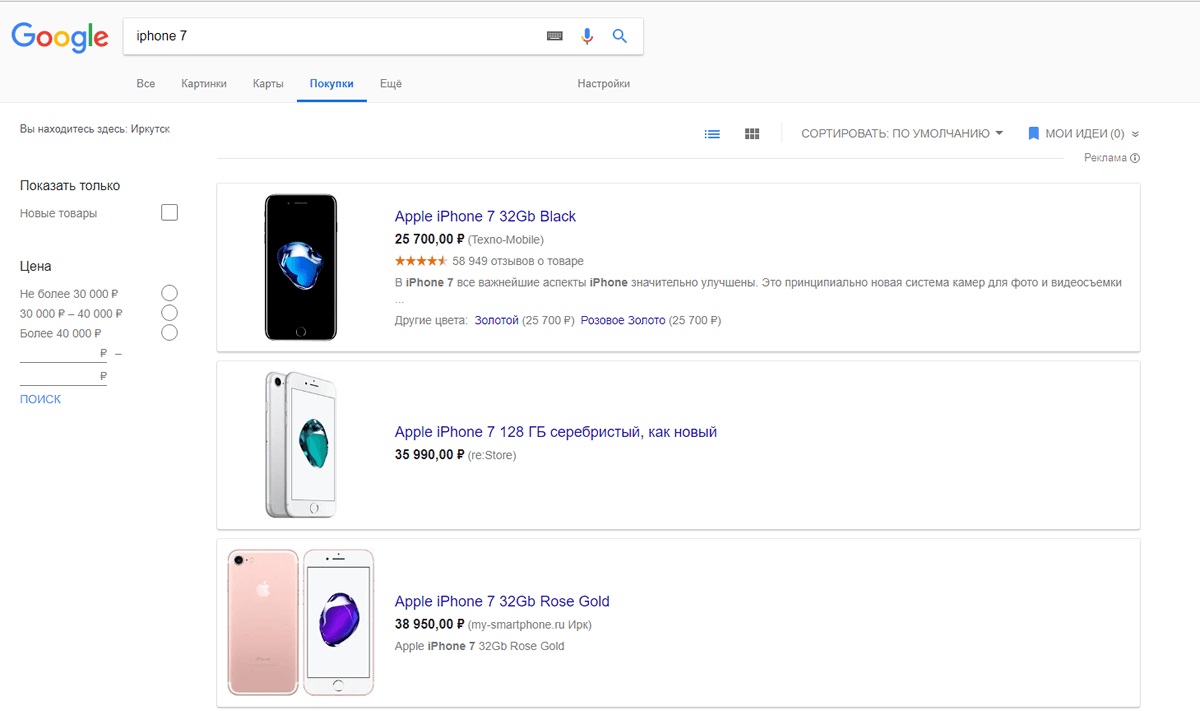
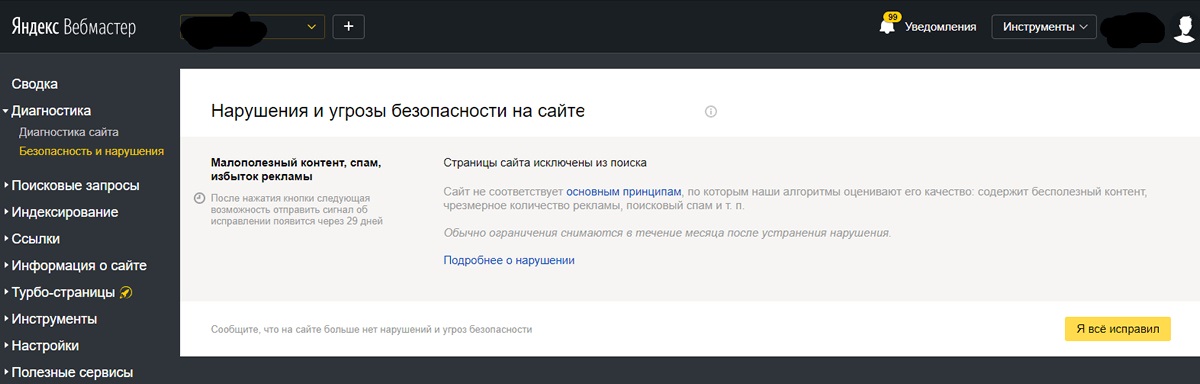

 |
Материал не ориентирован на аудиторию SEO-гуру В январе 2006 г. на заре своего существования SEOnews опубликовал подробную инструкцию по использованию файла robots.txt. И вот спустя 7 лет аудитории |
РэдЛайн, создание сайта, заказать сайт, разработка сайтов, реклама в Интернете, продвижение, маркетинговые исследования, дизайн студия, веб дизайн, раскрутка сайта, создать сайт компании, сделать сайт, создание сайтов, изготовление сайта, обслуживание сайтов, изготовление сайтов, заказать интернет сайт, создать сайт, изготовить сайт, разработка сайта, web студия, создание веб сайта, поддержка сайта, сайт на заказ, сопровождение сайта, дизайн сайта, сайт под ключ, заказ сайта, реклама сайта, хостинг, регистрация доменов, хабаровск, краснодар, москва, комсомольск |
|
Материал не ориентирован на аудиторию SEO-гуру В январе 2006 г. на заре своего существования SEOnews опубликовал подробную инструкцию по использованию файла robots.txt. И вот спустя 7 лет аудитории |
РэдЛайн, создание сайта, заказать сайт, разработка сайтов, реклама в Интернете, продвижение, маркетинговые исследования, дизайн студия, веб дизайн, раскрутка сайта, создать сайт компании, сделать сайт, создание сайтов, изготовление сайта, обслуживание сайтов, изготовление сайтов, заказать интернет сайт, создать сайт, изготовить сайт, разработка сайта, web студия, создание веб сайта, поддержка сайта, сайт на заказ, сопровождение сайта, дизайн сайта, сайт под ключ, заказ сайта, реклама сайта, хостинг, регистрация доменов, хабаровск, краснодар, москва, комсомольск |
Дайджест новых статей по интернет-маркетингу на ваш email
Новые статьи и публикации
- 2024-04-17 » 23 сервиса для эффективного экспресс-аудита любого сайта
- 2024-04-08 » Яндекс переходит на новую версию Wordstat
- 2024-04-08 » Яндекс интегрировал в свой облачный сервис эмпатичную нейросеть
- 2024-04-08 » Новая версия нейросети Claude превзошла по мощности аналоги Google и OpenAI
- 2024-04-08 » Как пользоваться GPT 4 и Claude бесплатно и без VPN
- 2024-03-13 » Стратегии SEO на 2024 год
- 2024-03-13 » Как использовать анимацию с помощью JavaScript-библиотеки GSAP
- 2024-03-13 » Использование GSAP 3 для веб-анимации
- 2024-03-13 » Cогласование топографической съёмки с эксплуатирующими организациями
- 2024-02-19 » Теряются лиды? Как настроить сквозную аналитику
- 2024-02-17 » Мерч и IT: на что обратить внимание в 2024 году
- 2024-02-16 » Копируем с RSync: основные примеры синхронизации файлов
- 2024-02-15 » Лучшие noCode AI платформы для создания диалоговых ботов
- 2024-02-14 » Факторы ранжирования Google 2024 — исследование Semrush
- 2024-02-12 » Перенос сайта на другой хостинг
- 2024-02-05 » В России сформирован реестр хостинг-провайдеров
- 2024-02-04 » Использование SSH для подключения к удаленному серверу Ubuntu
- 2024-02-03 » Подключаемся к серверу за NAT при помощи туннеля SSH. Простая и понятная инструкция
- 2024-02-02 » Настройка CI/CD для Gitlab-репозитория: схемы и гайд по шагам
- 2024-02-01 » GitLab CI Pipeline. Запуск сценария через SSH на удаленном сервере
- 2024-01-29 » Introduction to GitLab’s CI/CD for Continuous Deployments
- 2024-01-26 » Настройка GitLab CI/CD
- 2024-01-25 » Установка shell gitlab runner
- 2024-01-25 » Установка и регистрация gitlab-runner в docker контейнере
- 2024-01-25 » Переменные Gitlab-Ci
- 2024-01-25 » Настройка CI/CD в GitLab для синхронизации проекта с веб-серверами
- 2024-01-25 » Копирование файлов scp
- 2024-01-21 » Бездепозитные бонусы от казино: обзор условий и правил использования
- 2024-01-18 » Современная обработка ошибок в PHP
- 2024-01-18 » Пример шаблона проектирования MVC в PHP

Все мы сидим в сточной канаве, но некоторые при этом смотрят на звезды Уайльд Оскар - (1854-1900) - английский писатель |
Мы создаем сайты, которые работают! Профессионально обслуживаем и продвигаем их !
Как мы работаем
Заявка
Позвоните или оставьте заявку на сайте.
Консультация
Обсуждаем что именно Вам нужно и помогаем определить как это лучше сделать!
Договор
Заключаем договор на оказание услуг, в котором прописаны условия и обязанности обеих сторон.
Выполнение работ
Непосредственно оказание требующихся услуг и работ по вашему заданию.
Поддержка
Сдача выполненых работ, последующие корректировки и поддержка при необходимости.

 Мы создаем практически любые сайты от продающих страниц до сложных, высоконагруженных и нестандартных веб приложений! Наши сайты это надежные маркетинговые инструменты для успеха Вашего бизнеса и увеличения вашей прибыли! Мы делаем красивые и максимально эффектные сайты по доступным ценам уже много лет!
Мы создаем практически любые сайты от продающих страниц до сложных, высоконагруженных и нестандартных веб приложений! Наши сайты это надежные маркетинговые инструменты для успеха Вашего бизнеса и увеличения вашей прибыли! Мы делаем красивые и максимально эффектные сайты по доступным ценам уже много лет! Комплексный подход это не просто продвижение сайта, это целый комплекс мероприятий, который определяется целями и задачами поставленными перед сайтом и организацией, которая за этим стоит. Время однобоких методов в продвижении сайтов уже прошло, конкуренция слишком высока, чтобы была возможность расслабиться и получать \ удерживать клиентов из Интернета, просто сделав сайт и не занимаясь им...
Комплексный подход это не просто продвижение сайта, это целый комплекс мероприятий, который определяется целями и задачами поставленными перед сайтом и организацией, которая за этим стоит. Время однобоких методов в продвижении сайтов уже прошло, конкуренция слишком высока, чтобы была возможность расслабиться и получать \ удерживать клиентов из Интернета, просто сделав сайт и не занимаясь им...
 Мы оказываем полный комплекс услуг по сопровождению сайта: информационному и техническому обслуживанию и развитию Интернет сайтов.
Мы оказываем полный комплекс услуг по сопровождению сайта: информационному и техническому обслуживанию и развитию Интернет сайтов.

 Контекстная реклама - это эффективный инструмент в интернет маркетинге, целью которого является увеличение продаж. Главный плюс контекстной рекламы заключается в том, что она работает избирательно.
Контекстная реклама - это эффективный инструмент в интернет маркетинге, целью которого является увеличение продаж. Главный плюс контекстной рекламы заключается в том, что она работает избирательно.