Советы по корректному использованию файла robots.txt
В одном из своих твитов я упомянул, что robots.txt это зло и чем он больше, тем больше зла он приносит сайту. Встретив много непонимания, в том числе и на данный момент, когда мнения оптимизаторов четко разделяются по этому вопросу, когда некоторые вебмастера используют старые рекомендации, хочется внести некую ясность в использование этого файла в текущих условиях.
Понятно, что в robots.txt используются разные директивы. Среди них есть много полезных:
- Host: для указания основного хоста для Яндекса
- Sitemap: для указания адреса карты сайта
- Crawl-Delay: для указания минимальной задержки между индексацией страниц (не для всех поисковиков).
Также есть директива Disallow (и Allow как противоположная). Именно о них и пойдет речь в данной статье.
С какими проблемами сталкиваются вебмастера, используя robots.txt?
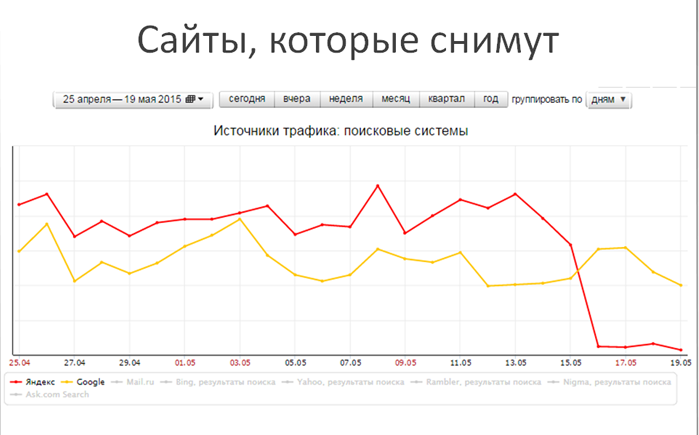
Первая и основная проблема, с которой сталкиваются вебмастера, это наличие в индексе Google страниц, закрытых в robots.txt. Считается, что если закрыть страницу или раздел в robots.txt, то она не попадет в индекс или выпадет из него, если там была. Это пока что работает так для Яндекса, Google воспринимает robots.txt по-другому.

Если обратиться к справке Google, то можно видеть, что robots.txt — это не правило, а рекомендация. И она означает “не сканировать страницу”, а не “не добавлять её в индекс”. Страница по прежнему может попасть в индекс, если на неё была найдена ссылка внутри сайта или где-то на внешнем ресурсе.
Вроде бы ничего страшного, но наличие подобных страниц в индексе, во-первых, плохо влияет на авторитет сайта (в связи с введением Пингвина, Яндекс пока работает по другому), и, во-вторых, подобный сниппет может снижать конверсию и ухудшать поведенческий фактор в поиске.
Для закрытия дублей страниц лучше использовать внутренние средства CMS, а не стараться упростить себе жизнь файлом robots.txt. Тем более, что файл может по каким-то причинам быть недоступен (перенесли на другой сервер, забыли, переименовали и так далее) и в таком случае все закрытое становится резко открытым (наверное как в случае с прошлой утечкой информации из wiki.yandex-team.ru).
Во-вторых, закрывая всё подряд, можно случайно закрыть важные вещи. Например, закрывая в Wordpress всю папку /wp-content/, можно остаться без трафика по изображениям, которые хранятся в /wp-content/uploads/.

Тут хранятся изображения, но в поиске по картинкам их нет:

Так что, получается лучше совсем не использовать robots.txt? В некоторых случаях он всё же полезен (особенно, когда мы прописываем главное зеркало для Яндекса).
Для чего я рекомендую использовать robots.txt
- Для закрытия всего сайта при его разработке
Чтобы заранее в индекс не попало ничего лишнего. - Для закрытия сайта от левых поисковиков.
Например, Рунетовским сайтам нет смысла показываться в Yahoo! Если в этом поисковике нет целевой аудитории, то можно смело закрывать сайт, дабы не нагружать дополнительно свои сервера. - Для закрытия приватных разделов сайта от глаз робота.
Чтобы приватные данные (типа номера кредитных карт :) пароли или смс-ки пользователей) не попадали в индекс. Хотя логично эти разделы вообще не иметь открытыми на сайте. - Для снятия нагрузки на сервер
Если, к примеру, на вашем очень популярном сайте много функционала по сотрировке товара, или какие-то фильтры, которые требуют больших серверных ресурсов, можно не пускать робота к этим страницам, чтобы снять нагрузку. Хотя, опять же, логино было бы сделать функционал сортировки невидимым для робота в самой CMS, чем перекладывать ответственность на файл robots.txt.
Для чего я бы не рекомендовал использовать robots.txt
- Для закрытия индексации страниц пейджинга, сортировки, поиска
От дублей следует избавляться средствами CMS, например, 301 редиректом, тегом rel=canonical (который специально для этого был создан), 404 ошибкой или мета тегом robots noindex. - Для удаления уже существующих в индексе страниц
Частая ошибка вебмастеров, когда пытаются удалить страницы из индекса роботсом. Поисковый робот не сможет переиндексировать страницу и удалить её, если вы закроете к ней доступ через роботс. - Для закрытия админ-панели
Путь к админке виден в роботс. Так на конференции Optimization.by мы с коллегами злоумышленно получили доступ к одной админке сайта про курсовые работы, путь к которой узнали через robots.txt, а пароли были стандартные admin:admin. - Для закрытия других страниц, которые вы не хотите видеть в индексе
Используйте для этого любые другие методы
Любые комментарии приветствуются. Как вы используете свой robots.txt и сталкивались ли раньше с описанными проблемами?













 |
В одном из своих твитов я упомянул, что robots.txt это зло и чем он больше, тем больше зла он приносит сайту. Встретив много непонимания, в том числе и на данный момент, когда мнения оптимизаторов |
РэдЛайн, создание сайта, заказать сайт, разработка сайтов, реклама в Интернете, продвижение, маркетинговые исследования, дизайн студия, веб дизайн, раскрутка сайта, создать сайт компании, сделать сайт, создание сайтов, изготовление сайта, обслуживание сайтов, изготовление сайтов, заказать интернет сайт, создать сайт, изготовить сайт, разработка сайта, web студия, создание веб сайта, поддержка сайта, сайт на заказ, сопровождение сайта, дизайн сайта, сайт под ключ, заказ сайта, реклама сайта, хостинг, регистрация доменов, хабаровск, краснодар, москва, комсомольск |
|
В одном из своих твитов я упомянул, что robots.txt это зло и чем он больше, тем больше зла он приносит сайту. Встретив много непонимания, в том числе и на данный момент, когда мнения оптимизаторов |
РэдЛайн, создание сайта, заказать сайт, разработка сайтов, реклама в Интернете, продвижение, маркетинговые исследования, дизайн студия, веб дизайн, раскрутка сайта, создать сайт компании, сделать сайт, создание сайтов, изготовление сайта, обслуживание сайтов, изготовление сайтов, заказать интернет сайт, создать сайт, изготовить сайт, разработка сайта, web студия, создание веб сайта, поддержка сайта, сайт на заказ, сопровождение сайта, дизайн сайта, сайт под ключ, заказ сайта, реклама сайта, хостинг, регистрация доменов, хабаровск, краснодар, москва, комсомольск |
Дайджест новых статей по интернет-маркетингу на ваш email
Новые статьи и публикации
- 2024-04-22 » Комментирование кода и генерация документации в PHP
- 2024-04-22 » SEO в России и на Западе: в чем основные отличия
- 2024-04-22 » SEO для международного масштабирования
- 2024-04-22 » Как использовать XML-карты для продвижения сайта
- 2024-04-22 » Цифровой маркетинг: инструменты для продвижения и рекламы в 2024 году
- 2024-04-22 » Что такое CSS-модули и зачем они нам?
- 2024-04-17 » 23 сервиса для эффективного экспресс-аудита любого сайта
- 2024-04-08 » Яндекс переходит на новую версию Wordstat
- 2024-04-08 » Яндекс интегрировал в свой облачный сервис эмпатичную нейросеть
- 2024-04-08 » Новая версия нейросети Claude превзошла по мощности аналоги Google и OpenAI
- 2024-04-08 » Как пользоваться GPT 4 и Claude бесплатно и без VPN
- 2024-03-13 » Стратегии SEO на 2024 год
- 2024-03-13 » Как использовать анимацию с помощью JavaScript-библиотеки GSAP
- 2024-03-13 » Использование GSAP 3 для веб-анимации
- 2024-03-13 » Cогласование топографической съёмки с эксплуатирующими организациями
- 2024-02-19 » Теряются лиды? Как настроить сквозную аналитику
- 2024-02-17 » Мерч и IT: на что обратить внимание в 2024 году
- 2024-02-16 » Копируем с RSync: основные примеры синхронизации файлов
- 2024-02-15 » Лучшие noCode AI платформы для создания диалоговых ботов
- 2024-02-14 » Факторы ранжирования Google 2024 — исследование Semrush
- 2024-02-12 » Перенос сайта на другой хостинг
- 2024-02-05 » В России сформирован реестр хостинг-провайдеров
- 2024-02-04 » Использование SSH для подключения к удаленному серверу Ubuntu
- 2024-02-03 » Подключаемся к серверу за NAT при помощи туннеля SSH. Простая и понятная инструкция
- 2024-02-02 » Настройка CI/CD для Gitlab-репозитория: схемы и гайд по шагам
- 2024-02-01 » GitLab CI Pipeline. Запуск сценария через SSH на удаленном сервере
- 2024-01-29 » Introduction to GitLab’s CI/CD for Continuous Deployments
- 2024-01-26 » Настройка GitLab CI/CD
- 2024-01-25 » Установка shell gitlab runner
- 2024-01-25 » Установка и регистрация gitlab-runner в docker контейнере

Каждый человек имеет право на собственное мнение — при условии, что оно совпадает с нашим Шоу Джордж Бернард - 1856-1950) - английский писатель. В своем творчестве ниспровергал догматизм и предвзятость, традиционность представлений |
Мы создаем сайты, которые работают! Профессионально обслуживаем и продвигаем их !
Как мы работаем
Заявка
Позвоните или оставьте заявку на сайте.
Консультация
Обсуждаем что именно Вам нужно и помогаем определить как это лучше сделать!
Договор
Заключаем договор на оказание услуг, в котором прописаны условия и обязанности обеих сторон.
Выполнение работ
Непосредственно оказание требующихся услуг и работ по вашему заданию.
Поддержка
Сдача выполненых работ, последующие корректировки и поддержка при необходимости.

 Мы создаем практически любые сайты от продающих страниц до сложных, высоконагруженных и нестандартных веб приложений! Наши сайты это надежные маркетинговые инструменты для успеха Вашего бизнеса и увеличения вашей прибыли! Мы делаем красивые и максимально эффектные сайты по доступным ценам уже много лет!
Мы создаем практически любые сайты от продающих страниц до сложных, высоконагруженных и нестандартных веб приложений! Наши сайты это надежные маркетинговые инструменты для успеха Вашего бизнеса и увеличения вашей прибыли! Мы делаем красивые и максимально эффектные сайты по доступным ценам уже много лет! Комплексный подход это не просто продвижение сайта, это целый комплекс мероприятий, который определяется целями и задачами поставленными перед сайтом и организацией, которая за этим стоит. Время однобоких методов в продвижении сайтов уже прошло, конкуренция слишком высока, чтобы была возможность расслабиться и получать \ удерживать клиентов из Интернета, просто сделав сайт и не занимаясь им...
Комплексный подход это не просто продвижение сайта, это целый комплекс мероприятий, который определяется целями и задачами поставленными перед сайтом и организацией, которая за этим стоит. Время однобоких методов в продвижении сайтов уже прошло, конкуренция слишком высока, чтобы была возможность расслабиться и получать \ удерживать клиентов из Интернета, просто сделав сайт и не занимаясь им...
 Мы оказываем полный комплекс услуг по сопровождению сайта: информационному и техническому обслуживанию и развитию Интернет сайтов.
Мы оказываем полный комплекс услуг по сопровождению сайта: информационному и техническому обслуживанию и развитию Интернет сайтов.

 Контекстная реклама - это эффективный инструмент в интернет маркетинге, целью которого является увеличение продаж. Главный плюс контекстной рекламы заключается в том, что она работает избирательно.
Контекстная реклама - это эффективный инструмент в интернет маркетинге, целью которого является увеличение продаж. Главный плюс контекстной рекламы заключается в том, что она работает избирательно.