Продвижение и раскрутка сайта в Rambler
Продвижение и раскрутка сайта в Рамблер имеет свою специфику. Рамблер заметно медленнее, чем Яндес, или Гугль проводит индексацию страниц. Информация, которая рассмотрена ниже поможет учесть особенности продвижения сайта в Рамблер.
Вместо введения.
Раскрутка сайта в Рамблер имеет ряд особенностей. Поисковая машина Рамблер – часто полагается на рейтинг Rambler TOP100, при этом индексация сайтов и новых страниц происходит довольно медленно.
Из личного опыта можно утверждать, что поисковая система Рамблер любит хороший, уникальный контент больше остальных поисковых систем, также на выдачу Рамблера влияет наличие и положение в рейтинге Rambler TOP100 и Рамблер любит медленный естественный прирост ссылок.
Т.к. апдейты в Rambler происходят гораздо реже, чем в Google и Яndex, то гарантии на продвижение сайта в Рамбер можно давать только при сроке не менее 6 месяцев. При этом сайт нужно продвигать комплексно с постоянным улучшением контента.
Особенности работы поисковой машины Рамблер.
Поисковая машина Rambler рассчитывает для каждого документа коэффициент популярности. Вот что сказано на сайте Рамблера об этом коэффициенте: "Данный коэффициент, как и алгоритм PageRank, основан на учете гиперссылок между страницами сети, однако наша реализация дополнительно использует данные о реальной посещаемости страниц, полученные от счетчика Top100. Дело в том, что "классические" ссылочные алгоритмы фактически учитывают мнение только одной категории пользователей сети - web-мастеров. Действительно, если большому количеству web-мастеров нравится тот или иной ресурс, они размещают на него ссылки. Обычные пользователи, как правило, созданием страниц и сайтов не занимаются, и поэтому учесть их мнение оказывается невозможно. Счетчик Top100 как раз и предназначен для того, чтобы сделать коэффициент популярности более справедливым".
Однако, судя по всему, в последнее время данные о посещаемости документов, полученные от счетчика Top100, оказывают все меньшее и меньшее влияние на коэффициент популярности, так как счетчик не в состоянии противостоять массовым накруткам, практикуемым владельцами некоторых сайтов. Соответственно, все большее значение приобретает составляющая, вычисляемая на основе учета гиперссылок между страницами сети.
Необходимо, заметить, что некоторые документы и даже целые сайты в поисковых машинах могут по той или иной причине исключаться из процесса расчета ранга документа, на который они ссылаются. Так, например, в Яндексе для этих целей существует так называемый "непот-фильтр", который накладывается на ресурсы, находящиеся на бесплатных хостингах, но не описанные в Яндекс-каталоге, ресурсы со свободным размещением ссылок (например, гостевые книги, доски объявлений), сайты, размещающие на своих страницах ссылки, невидимые пользователю и т.п.
Резюмируя вышесказанное, можно сказать, что для повышения ранга страницы необходимо работать над тем, чтобы как можно большее количество документов сети ссылалось на него. Делать это можно различными способами - с помощью обмена ссылками с другими сайтами, регистраций в каталогах и различных тематических ресурсах и т.д. Идеальный способ - сделать свой сайт настолько уникальным и интересным, чтобы владельцы других ресурсов сами считали необходимым поставить ссылку на него. Не следует также забывать, что при расчете ранга документа учитываются как внешние, так и внутренние ссылки. Поэтому грамотная перелинковка документов внутри сайта позволяет повысить ранг самых важных из них с точки зрения содержащейся информации. Наиболее важные в этом смысле документы обязательно должны иметь ссылку с главной страницы сайта, которая, как правило, имеет максимальный ранг среди всех страниц сайта вследствие того, что на нее указывает большинство внешних ссылок на сайт.
Механизм поисковой системы Рамблер.
Полнота поиска в Рамблер.
Полнота - это одна из основных характеристик поисковой системы, которая представляет собой отношение количества найденных по запросу документов к общему числу документов в Интрнете, удовлетворяющих данному запросу. Например, если в сети Интернет имеется 100 страниц, содержащих словосочетание “Красная площадь”, а по соответствующему запросу было найдено всего 70 из них, то полнота поиска будет 0,7. Чем полнее поиск, тем меньше вероятность, что пользователь не сможет найти нужный ему документ, при условии, что он вообще существует в Интернете.
Полнота поиска в большой мере зависит от работы системы сбора и обработки информации. В связи с постоянным ростом количества документов в сети, эта система в первую очередь должна быть масштабируемой. В Рамблере масштабируемость достигается за счет параллельного исполнения задачи произвольным количеством машин.
Сбором информации занимается робот-паук, который обходит страницы с заданными URL и скачивает их в базу данных, а затем архивирует и перекладывает в хранилище суточными порциями. Робот размещается на нескольких машинах, и каждая из них выполняет свое задание. Так, робот на одной машине может качать новые страницы, которые еще не были известны поисковой системе, а на другой - страницы, которые ранее уже были скачены не менее месяца, но и не более года назад. Хранилище у всех машин едино. При необходимости работу можно распределить другим способом, например, разбив список URL на 10 частей и раздав их 10 машинам. Параллельная работа программы позволяет легко выдерживать дополнительную нагрузку: при увеличении количества страниц, которые нужно обойти роботу, достаточно просто распределить задачу на большее число машин.
В хранилище информация в сжатом виде собирается и разбивается на куски по 50 Мб. Эти части постепенно распределяются между 70 машинами, на которых запущена программа-индексатор. Как только индексатор на одной из машин заканчивает обработку очередной части страниц, он обращается за следующей порцией. В результате на первом этапе формируется много маленьких индексных баз, каждая из которых содержит информацию о некоторой части Интернета. Таким образом, вся интеллектуальная обработка данных осуществляется параллельно, поэтому ускорение процесса индексации достигается простым добавлением машин в систему.
После того, как все части информации обработаны, начинается объединение результатов. Благодаря тому, что частичные индексные базы и основная база, к которой обращается поисковая машина, имеют одинаковый формат, процедура объединения является простой и быстрой операцией, не требующей никаких дополнительных модификаций частичных индексов. Основная база участвует в анализе как одна из частей нового индекса. Так, если объединяются 70 новых частей, то в анализе участвует 71 фрагмент (70 новых + основная база предыдущей редакции). Кроме того, единый формат позволяет проводить тестирование частичных баз еще до объединения их с основной, и обнаруживать ошибки на более раннем этапе.
Специальная программа (“сливатор”) составляет таблицы перенумерации документов базы. Содержимое всех частей объединяется. Среди страниц с одинаковыми адресами выбирается наиболее свежая версия; если при скачивании URL последней информацией была ошибка 404 (запрашиваемая страница не существует), она временно удаляется из индексной базы. Параллельно осуществляется склейка дублей: страницы, которые имеют одинаковое содержимое, но различные URL, объединяются в один документ.
Сборка единой базы из частичных индексных баз представляет собой простой и быстрый процесс. Сопоставление страниц не требует никакой интеллектуальной обработки и происходит со скоростью чтения данных с диска. Если информации, которая генерируется на машинах-индексаторах, получается слишком много, то процедура “сливания” частей проходит в несколько этапов. В начале частичные индексы объединяются в несколько промежуточных баз, а затем промежуточные базы и основная база предыдущей редакции пересекаются. Таких этапов может быть сколько угодно. Промежуточные базы могут сливаться в другие промежуточные базы, а уже потом объединяться окончательно. Поэтапная работа незначительно замедляет формирование единого индекса и не отражается на качестве результатов.
Точность поиска в Рамблер.
Точность - еще одна основная характеристика поисковой машины, которая определяется как степень соответствия найденных документов запросу пользователя. Например, если по запросу “Красная площадь” находится 150 документов, в 70 из них содержится словосочетание “Красная площадь”, а в остальных просто присутствуют эти слова (“красная баба кричала на всю площадь”), то точность поиска считается равной 70/150 (~0,5). Чем точнее поиск, тем быстрее пользователь находит нужные ему документы, тем меньше “мусора” среди них встречается, тем реже найденные документы не соответствуют запросу.
Повышение точности в поисковой машине Рамблер достигается за счет использования различных технологий на всех этапах обработки и поиска информации. Одним из наиболее интересных процессов является распознавание грамматических омонимов. Омонимы - это слова, которые имеют одинаковое написание, но различный смысл. Различают лексические и грамматические омонимы. Лексические омонимы относятся к одной части речи, как, например, существительное “бор”: хвойный лес, стальное сверло и химический элемент. Грамматические омонимы относятся к разным частям речи, поэтому по написанию у них обычно совпадают только отдельные формы. Примерами грамматических омонимов могут служить слова “печь” - существительное русская “печь” и глагол “печь” пирожки; “рядовой” - прилагательное “рядовой” сотрудник и существительное “рядовой” Иванов.
Омонимы не только увеличивают размер индексной базы (так как для каждого такого слова приходится хранить все его возможные значения), но и отрицательно сказываются на точности поиска. Если пользователь ищет слово “данные”, ему неинтересно получить в найденном все документы, которые содержат слово “дать”. Для того, чтобы результаты поиска были точнее, модуль синтаксического анализа проводит разбор окружения слов-омонимов с целью установления их наиболее вероятных значений. Например, если рядом со словом “печь” стоит существительное (“пирожки”, “картошка”), то с высокой вероятностью “печь” в данном контексте является глаголом. На сегодняшний день анализатор способен распознавать значения только грамматических омонимов.
Синтаксический анализ позволяет также с определенной вероятностью распознавать некоторые имена собственные. Например, если в тексте несколько слов подряд написано с большой буквы, они чаще всего представляют собой имя собственное (Петр Петрович, Московский Государственный Университет). Данные о таких конструкциях учитываются при индексации и обработке запроса.
Еще один способ повышения точности поиска - это выделение устойчивых обозначений и поиск их как отдельных лексических единиц. На сегодняшний день в Рамблере реализована система распознавания таких конструкций, например C++, б/у, п/п-к. Если по запросу С++ поднимать все тексты, в которых присутствуют латинская буква С, а также знак +, то получится огромное количество документов, далеко не все из которых соответствуют запросу; кроме того, это большая работа, значительно увеличивающая время поиска.
Огромную роль в повышении точности поиска играет ранжирование. Пользователь очень редко просматривает больше трёх страниц с результатами поиска. Поэтому субъективно он оценивает точность по “верхним” документам. Даже если нужный документ найден поисковой машиной, но расположен на двухсотой позиции, скорее всего, он никогда не будет найден пользователем.
По умолчанию в Рамблере результаты ранжируются по степени соответствия запросу (релевантности) и группируются по сайтам. При ранжировании оцениваются различные характеристики текстов, такие как:
- Количество вхождений слов (словосочетаний) в документ - чем больше раз словосочетание “Красная площадь” присутствует в тексте, тем выше вероятность, что в нем действительно говорится о Красной площади;
- Расположение слов запроса в документе - если словосочетание “Красная площадь” присутствует в заголовках или названии документа, то документ с большей вероятностью посвящен Красной площади;
- Формы слов запроса - преимущество отдается вхождениям, в которых слова имеют тот же падеж, число, склонение и т.д., что и в запросе пользователя (“Красная площадь”, а не “Красной площадью”). Помимо точного совпадения, выделяются две группы форм слов - близкие и далекие. Близкими считаются изменения по падежам, склонениям, спряжениям, числам и родам. Далекими формами являются причастия, деепричастия и т.п. При ранжировании преимущество отдается близким формам слов запроса.
- Относительная частота (отношение количества вхождений слов запроса в документ к общему количеству слов в документе) - если словосочетание встречается 10 раз в документе из 100 слов, то он скорее соответствует запросу, чем если оно встречается те же 10 раз в документе из 20 тысяч слов;
- Расстояние между словами запроса - если запрос состоит из нескольких слов, то в найденных документах оценивается, насколько близко друг от друга расположены эти слова. Преимущество отдается документам, в которых слова запроса находятся ближе друг к другу, потому что в этом случае они с большей вероятностью связаны между собой. Например, если слово “Красная” расположено в тексте на 5 позиции, а слово “площадь” - на 650, то скорее всего в документе речь идет не о Красной площади.
- Посещаемость документа - в некоторых случаях поисковой машине Рамблер известна посещаемость страниц (если эти страницы являются участниками рейтинга Тор 100). Преимущество отдается более посещаемым ресурсам.
- Ссылочный вес документа - при ранжировании учитывается ссылочный вес страницы, рассчитанный на основании учета гиперссылок, содержащих слова запроса. Так, если на документ словами “Красная площадь” ссылается большое количество авторитетных страниц, то ему отдается приоритет по запросу Красная площадь.
Помимо автоматических способов увеличения точности поиска, существуют различные средства, с помощью которых пользователь сам может уточнить поиск по отдельным запросам. В первую очередь к ним относится специальный язык поискового запроса, используя который можно ограничивать количество найденных документов. Например, запрос или его часть, взятые в кавычки, обрабатываются буквально, с учетом всех стоп-слов, форм, порядка, знаков препинания. Это повышает точность поиска, но уменьшает его полноту: если часть, заключенная в кавычки, неточна, нужный документ найден не будет.
Использование логического оператора OR (ИЛИ) позволяет расширить сферу поиска и увеличить его полноту, в то время как оператор NOT (И-НЕ), наоборот, повышает точность поиска за счет нахождения документов, которые содержат одни слова запроса и не содержат другие. Для повышения точности можно также задавать расстояние между словами. Если в искомом словосочетании порядок слов обычно сохраняется (например, Красная площадь), то в запросе для повышения точности имеет смысл ограничить расстояние, указав его в скобках через запятую: (2, Красная площадь). Это позволит отсеять документы, в которых слова красная и площадь не расположены рядом, а разбросаны по тексту.
Увеличить точность можно с помощью использования поиска в найденном. Каждый следующий, уточняющий поиск, проводится уже не по всей индексной базе, а только по результатам предыдущего поиска. Таким образом, круг найденных документов сужается. Например, если дать запрос Красная площадь, а затем, провести поиск в найденном по запросу Москва, то результат будет содержать только те документы, в которых говорится о Красной площади города Москвы.
Актуальность запросов в Рамблер.
Актуальность - не менее важная характеристика поиска, которая определяется временем, проходящим с момента публикации документов в сети Интернет, до занесения их в индексную базу. Например, на следующий день после теракта в Тушино огромное количество пользователей обратились к поисковой машине Рамблер с соответствующими запросами. Объективно с момента публикации новостной информации на эту тему прошло меньше суток. Однако основные документы уже были заиндексированы и доступны для поиска, благодаря существованию “быстрой базы”, которая обновляется два раза в день, а при необходимости может обновляться быстрее.
На сегодняшний день индексная база поисковой системы Рамблер состоит из 8 частей, каждая из которых живет своей независимой жизнью. Весь Интернет условно разделен на 7 секторов и называется своим цветом: красный, оранжевый, желтый, зеленый, голубой, синий, фиолетовый. Сайт компании Рамблер относится к голубому сектору. Информация о web-ресурсах каждого сектора хранится в соответствующей части индексной базы. Восьмая часть - “быстрая база” - включает в себя страницы, на которых размещен счетчик Тор 100 и которые еще не успели попасть в основную индексную базу.
Все части индексной базы собираются и обновляются по отдельности. Так, сегодня происходит переиндексация и обновление красного сектора, завтра - оранжевого и желтого, послезавтра - зеленого и т.д. Благодаря такому ступенчатому алгоритму в поисковой машине каждый день появляется свежая информация об одной седьмой части Интернета. Полный цикл обновления занимает около недели. При этом сбор информации происходит параллельно, а непосредственно на изготовление индекса документов одного сектора уходит всего несколько часов. Поэтому существует принципиальная возможность обновлять индексную базу быстрее.
Разделение Интернета на 7 секторов условно. При необходимости он может быть разбит на 10, 20 или 40 секторов, каждый из которых будет обрабатываться автономно. В такой системе заложена возможность значительного увеличения нагрузки. С ростом объема информации в сети Интернет растет и индексная база поисковой машины. Постепенно переиндексация и сборка базы начинает занимать все больше времени, а процесс обновления индекса становится более громоздким. Поступление новых данных затягивается, информация начинает терять свою актуальность. Возможность “передела” Интернета на большее число секторов позволяет удерживать размер каждой части базы в оптимальном диапазоне, контролировать время ее сборки и обновления.
“Быстрая база” отличается от остальных частей индекса меньшим объемом и очень оперативным обновлением: время ее построения занимает около двух часов. В базе содержится информация о страницах, на которых был установлен счетчик Тор 100. Участниками рейтинга Тор 100 являются новостные порталы, сайты крупных компаний, Интернет-магазины, форумы, - все наиболее популярные ресурсы в сети. Каждый раз при установке счетчика на новую страницу сайта, зарегистрированного в Тор 100, информация передается в поисковую систему. Страница ищется во всех цветах основной базы и, если она еще не известна поисковой системе, отправляется в очередь на обработку. Перед обработкой страницы дополнительно фильтруются, из них отбираются самые посещаемые. Таким образом, “сливки” с Интернета собираются два раза в день.
“Быстрая база” представляет собой разумное решение проблемы актуальности данных в поиске. Информационное агентство может выложить новость через десять минут после ее появления, потому что тратит время только на верстку страницы. Поисковая машина должна сначала заиндексировать текст, а на это требуется гораздо больше времени. “Быстрая база” охватывает все ресурсы Интернет, зарегистрированные в Тор 100, на которых был размещен счетчик, и которые еще не успели попасть в основную базу. При этом индексируются как страницы с новостями, так и другие свежие документы, появившиеся в Тор 100. В результате через сутки после теракта в поиске Рамблера была доступна не только основная информация, опубликованная на сайтах новостных агентств, которую можно найти и прочитать в разделах новостей, но и комментарии, высказывания очевидцев, обсуждения на форумах, все, что было к этому времени опубликовано на наиболее посещаемых страницах Интернета.
Скорость поиска в Рамблер.
Скорость поиска тесно связана с его устойчивостью к нагрузкам. На сегодняшний день в рабочие часы к поисковой машине Рамблер приходит около 60 запросов в секунду. Такая загруженность требует сокращения времени обработки отдельного запроса. Здесь интересы пользователя и поисковой системы совпадают: посетитель хочет получить результаты как можно быстрее, а поисковая машина должна отрабатывать запрос максимально оперативно, чтобы не тормозить вычисление следующих. Схематично обработка поискового запроса изображена на рисунке 1.
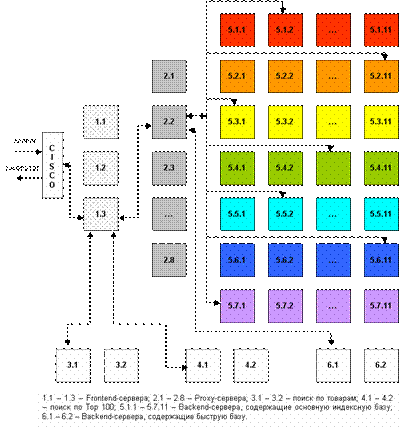
Запрос поступает в поисковую систему через маршрутизатор Cisco 6000 series. Cisco передает его наименее загруженной машине первого уровня - frontend (1.1 - 1.3, на рис. машине 1.3). Frontend, в свою очередь, отправляет запрос дальше, на один из семи proxy-серверов, также выбирая наиболее свободный сервер (2.1 - 2.7, на рис. машине 2.2). Одновременно frontend отправляет запрос на машины, осуществляющие поиск по товарам (3.1 - 3.2, на рис. машине 3.1) и по базе Тор 100 (4.1 - 4.2, на рис. машине 4.1). На proxy проводится поиск по ссылочному индексу, и его результаты вместе с поисковым запросом передаются на машины, которые содержат основную индексную базу, - backends (5.1.х - 5.7.х, на рис. машинам 5.1.2, 5.2.10, 5.3.1 и т.д.) Та же информация отправляется на машины с “быстрой базой” (6.1 - 6.2, на рис. 6.1).
На текущий момент в поиск включено около 70 backend’ов. Они сгруппированы по 10 машин, и каждая группа содержит копию одной из частей поискового индекса. Таким образом, информация о сайтах, условно входящих в красный сектор Интернета, находится на backend’ах первой группы (5.1.1 - 5.1.10 на рис), оранжевый сектор - на backend’ах второй группы (5.2.1 - 5.2.10) и т.д. Proxy-сервер выбирает наименее загруженный backend в каждой группе машин и отправляет на него поисковый запрос с результатами ссылочного поиска. На backend’ах осуществляется поиск по частям индексной базы и ранжирование с учетом результатов поиска по ссылочному индексу. При ранжировании для всех найденных документов высчитываются веса по конкретному запросу.
После того, как запрос обработан на backend’ах, информация о результатах и ранжировании отдается обратно на proxy-сервер. Туда же поступают отсортированные результаты с машин “быстрой базы”. Proxy интегрирует данные, полученные с восьми машин: клеит дубли, объединяет зеркала сайтов, переранжирует документы в общий список по весам, рассчитанным на backend’ах. Так, первым в списке найденного может быть документ с машины 5.3.1, вторым и третьим - с 6.1, четвертым - с 5.5.2 и т.д. На proxy-сервере также реализуется построение цитат к документам и подсветка слов запроса в тексте. Полученные результаты отдаются на frontend.
Помимо информации с proxy-сервера, frontend получает результаты из поиска по товарам и из базы Тор 100, отсортированные, с цитатами и подсветкой слов запроса. Frontend осуществляет окончательное объединение результатов, генерирует html со списком найденного, вставляет баннеры и перевязки (ссылки на различные разделы Рамблера) и отдает html Cisco, который маршрутизирует информацию пользователю.
Каждый из этапов обработки запроса многократно продублирован и защищен системой балансировки нагрузки. Благодаря дублированию информации поисковая система Рамблер является устойчивой к сбоям на отдельных участках, авариям, отказам оборудования. Если одна их машин перестала функционировать, нагрузка перераспределяется на другие машины, и выпадения документов из поиска не происходит. Масштабируемость достигается простым добавлением в систему машин соответствующего уровня. До недавнего времени в Рамблере работало 40 backend’ов. В связи с тем, что осенью нагрузка на поисковые системы обычно возрастает, число backend’ов было увеличено до 70, что позволило значительно ускорить вычисление запросов.
Еще один способ повышения скорости поиска - “кэширование”, сохранение информации о запросах и результатах поиска в буфере. Многие люди дают одни и те же поисковые запросы. Вычислять их каждый раз заново было бы неразумной тратой времени. Поэтому если запрос уже обрабатывался в течение некоторого интервала времени, результаты поиска отдаются пользователю “из кэша”.
Лингвистический анализ текста документов и запроса также позволяет ускорить обработку информации. Например, определение значения омонимов уменьшает количество нерелевантных запросу документов, которые нужно ранжировать и цитировать. Выделение устойчивых обозначений (С++, б/у) на этапах индексации и обработки запроса приводит одновременно к повышению точности и сокращению временных затрат на обработку каждого отдельного элемента обозначения (раньше запрос С++ обрабатывался как отдельно латинское С, отдельно плюс и еще один плюс. Запрос вычислялся долго, а среди результатов поиска было много нерелевантных документов, например, страницы, содержащие математические формулы и т.п.) С этой же целью используются словари стоп-слов. Стоп-слова - это наиболее частотные слова языка, которые встречаются практически в любом тексте и являются малоинформативными. В основном, это служебные слова - предлоги, частицы, артикли. Если нет специальных указаний, поисковая машина игнорирует стоп-слова, встречающиеся в запросе, чтобы не тратить время на обработку дополнительной информации, снижающей качество поиска.
Наглядность поиска в Рамблер.
Наглядность представления результатов является необходимым компонентом удобного поиска. На плохой витрине легко не заметить хороший товар. По большинству запросов поисковая машина находит сотни, а то и тысячи документов. В следствие нечеткости запросов или неточности поиска, даже первые страницы не всегда содержат только нужную информацию. Это означает, что пользователю часто приходится проводить свой собственный поиск внутри списка найденного. Различные элементы ответной страницы помогают ориентироваться в результатах поиска.
Группировка по сайтам предназначена для того, чтобы на странице можно было вывести как можно больше Интернет-ресурсов, релевантных запросу пользователя. Это бывает важным, когда необходимо получить информацию из различных источников. Если более информативной для посетителя является дата обновления или релевантность отдельных документов, в ответной странице Рамблера существует возможность сортировки по этим параметрам.
В некоторых случаях полезным бывает знание имени сайта. Если пользователя интересует конкретный Интернет-ресурс, имя может дать ему гораздо больше информации, чем заголовок страницы или цитата.
Если запросу соответствует больше одной страницы с сайта, то в качестве результата поиска предъявляется наиболее релевантная из них, а ниже располагается частичный список остальных документов. Это увеличивает количество потенциально полезной информации на ответной странице и часто позволяет уточнить поиск без дополнительного запроса.
Цитата помогает определить, насколько полезную информацию содержит найденный документ. Очень часто посетителю не требуется переходить по ссылке, чтобы обнаружить, что текст не соответствует его интересам и потребностям. Иногда ответ на вопрос пользователя содержится непосредственно в цитате документа. Это экономит время и повышает эффективность работы поисковой системы.
Восстановить текст - иногда единственный способ получить доступ к содержимому найденного документа. Ресурс бывает недоступен по разным причинам. Документ может быть удален, перенесен, изменен, но его текстовое содержание некоторое время сохраняется в индексной базе. Кроме того, внутри самого документа часто отсутствует навигация, позволяющая быстро найти фрагмент, релевантный запросу. В восстановленном тексте все слова запроса подсвечиваются.
Ассоциации представляют собой список запросов, которые часто подаются пользователями в течении одной поисковой сессии. Алгоритм построения ассоциаций устроен так, что они почти всегда связаны между собой по смыслу. В некоторых случаях ассоциации позволяют повысить качество поиска за счет уточнения запроса (запрос “отдых в Польше” - ассоциации “отдых в Польше с детьми”, “семейный отдых”, “пансионаты в Польше”), исправления распространенных ошибок (запрос “gjujlf” - ассоциация “погода”), возможности сориентироваться в незнакомой тематике (запрос “антибиотик” - ассоциации “сумамед”, “цифран”, “бисептол” и т.д.)
К чему стремится в своем развитии Рамблер.
Важнейшей задачей разработчиков является улучшение качества поиска, движение в сторону большей эффективности и удобства в использовании системы. С этой целью постоянно меняются поисковые алгоритмы, создаются дополнительные сервисы, дорабатывается дизайн.
Однако для того, чтобы выжить в мире динамичного Интернета, при разработке необходимо закладывать большой запас устойчивости, постоянно заглядывать в завтрашний день и примерять будущую нагрузку на сегодняшний поиск. Все, что сегодня программируется в Рамблере, рассчитано “на вырост”. Такой подход позволяет заниматься не только постоянной борьбой и приспособлением поисковой машины к растущим объемам информации, но и реализовывать что-то новое, действительно важное и нужное для повышения эффективности поиска в сети Интернет.















 |
Продвижение и раскрутка сайта в Рамблер имеет свою специфику. Рамблер заметно медленнее, чем Яндес, или Гугль проводит индексацию страниц. Информация, которая рассмотрена ниже поможет учесть |
РэдЛайн, создание сайта, заказать сайт, разработка сайтов, реклама в Интернете, продвижение, маркетинговые исследования, дизайн студия, веб дизайн, раскрутка сайта, создать сайт компании, сделать сайт, создание сайтов, изготовление сайта, обслуживание сайтов, изготовление сайтов, заказать интернет сайт, создать сайт, изготовить сайт, разработка сайта, web студия, создание веб сайта, поддержка сайта, сайт на заказ, сопровождение сайта, дизайн сайта, сайт под ключ, заказ сайта, реклама сайта, хостинг, регистрация доменов, хабаровск, краснодар, москва, комсомольск |
|
Продвижение и раскрутка сайта в Рамблер имеет свою специфику. Рамблер заметно медленнее, чем Яндес, или Гугль проводит индексацию страниц. Информация, которая рассмотрена ниже поможет учесть |
РэдЛайн, создание сайта, заказать сайт, разработка сайтов, реклама в Интернете, продвижение, маркетинговые исследования, дизайн студия, веб дизайн, раскрутка сайта, создать сайт компании, сделать сайт, создание сайтов, изготовление сайта, обслуживание сайтов, изготовление сайтов, заказать интернет сайт, создать сайт, изготовить сайт, разработка сайта, web студия, создание веб сайта, поддержка сайта, сайт на заказ, сопровождение сайта, дизайн сайта, сайт под ключ, заказ сайта, реклама сайта, хостинг, регистрация доменов, хабаровск, краснодар, москва, комсомольск |
Дайджест новых статей по интернет-маркетингу на ваш email
Новые статьи и публикации
- 2026-06-10 » Новые штрафы за неисполнение правил авторизации
- 2026-06-10 » Новая реальность: MAX под прицелом
- 2026-06-10 » Банки и операторов связи обяжут компенсировать похищенное мошенниками
- 2026-06-10 » Что такое «белый VPN» и чем он отличается от обычного?
- 2026-06-10 » Когда ИИ придумывает «факты»: анатомия кризиса вымышленной статистики
- 2026-06-10 » Автостратегии Яндекс.Директа: стоит ли использовать в 2026 году
- 2026-06-10 » SMM в 2026: от охватов к доверию — полный гид по стратегии
- 2026-06-10 » Яндекс.Директ вышел на новый уровень: теперь реклама в каналах «Макса» с точным таргетингом
- 2026-06-10 » РСЯ с 1 июля прекращает сотрудничество с партнерами-физлицами: что делать, чтобы не потерять доход
- 2026-06-10 » Макс становится супераппом: бесконтактная оплата через СБП в несколько секунд
- 2026-06-05 » Как Яндекс передал площадкам управление собственным контентом
- 2026-06-05 » Как создавать гайды и инструкции с помощью нейросетей
- 2026-06-05 » Попадет ли ваш сайт в ответы нейросетей
- 2026-06-05 » Как настроить контекстную рекламу в B2B, чтобы вы получали реальные сделки, а не сотни пустых заявок
- 2026-06-05 » Когда клиент говорит «нет», а конкурент уже набирает номер
- 2026-05-28 » Как выбрать и законно использовать стоковые фото для сайта
- 2026-05-28 » Как составить УТП для сайта, которое выделит вас на фоне тысяч серых шаблонов
- 2026-05-28 » «Белый перечень» онлайн-площадок, сохраняющих доступность при отключении мобильного интернета, — что в него попало
- 2026-05-28 » Не туда пишете: как фатальная ошибка в целевой аудитории убивает даже самый качественный контент
- 2026-05-28 » Как оставить отзыв на Яндекс Картах, чтобы модерация его точно пропустила
- 2026-05-23 » Красивые баннеры не продают: почему в 2026 году побеждает простота
- 2026-05-23 » Управление репутацией в 2026 году: нейровыдача как единая система влияния на клиента
- 2026-05-23 » 168-ФЗ 2026: инструкция по русификации сайта
- 2026-05-23 » Куда идти, если Телеграм окончательно заблокируют
- 2026-05-15 » Как происходит утечка данных и как с этим бороться
- 2026-05-15 » B2B-сайт не продает: 5 ошибок UX, которые превращают лидов в призраков
- 2026-05-15 » Как выбрать качественный и недорогой хостинг: правда о дешёвых тарифах
- 2026-05-15 » Зачем сайту SSL-сертификат и как получить его бесплатно прямо сейчас?
- 2026-05-15 » 7 причин медленной работы сайта: почему уходят клиенты и как это исправить
- 2026-05-07 » Будущее без cookies: альтернативные решения для идентификации пользователей

"Не пытайтесь перехитрить поисковые машины - надежность и доверие ценятся в сфере поискового маркетинга куда больше." |
Мы создаем сайты, которые работают! Профессионально обслуживаем и продвигаем их !
Как мы работаем
Заявка
Позвоните или оставьте заявку на сайте.
Консультация
Обсуждаем что именно Вам нужно и помогаем определить как это лучше сделать!
Договор
Заключаем договор на оказание услуг, в котором прописаны условия и обязанности обеих сторон.
Выполнение работ
Непосредственно оказание требующихся услуг и работ по вашему заданию.
Поддержка
Сдача выполненых работ, последующие корректировки и поддержка при необходимости.

 Мы создаем практически любые сайты от продающих страниц до сложных, высоконагруженных и нестандартных веб приложений! Наши сайты это надежные маркетинговые инструменты для успеха Вашего бизнеса и увеличения вашей прибыли! Мы делаем красивые и максимально эффектные сайты по доступным ценам уже много лет!
Мы создаем практически любые сайты от продающих страниц до сложных, высоконагруженных и нестандартных веб приложений! Наши сайты это надежные маркетинговые инструменты для успеха Вашего бизнеса и увеличения вашей прибыли! Мы делаем красивые и максимально эффектные сайты по доступным ценам уже много лет! Комплексный подход это не просто продвижение сайта, это целый комплекс мероприятий, который определяется целями и задачами поставленными перед сайтом и организацией, которая за этим стоит. Время однобоких методов в продвижении сайтов уже прошло, конкуренция слишком высока, чтобы была возможность расслабиться и получать \ удерживать клиентов из Интернета, просто сделав сайт и не занимаясь им...
Комплексный подход это не просто продвижение сайта, это целый комплекс мероприятий, который определяется целями и задачами поставленными перед сайтом и организацией, которая за этим стоит. Время однобоких методов в продвижении сайтов уже прошло, конкуренция слишком высока, чтобы была возможность расслабиться и получать \ удерживать клиентов из Интернета, просто сделав сайт и не занимаясь им...
 Мы оказываем полный комплекс услуг по сопровождению сайта: информационному и техническому обслуживанию и развитию Интернет сайтов.
Мы оказываем полный комплекс услуг по сопровождению сайта: информационному и техническому обслуживанию и развитию Интернет сайтов.

 Контекстная реклама - это эффективный инструмент в интернет маркетинге, целью которого является увеличение продаж. Главный плюс контекстной рекламы заключается в том, что она работает избирательно.
Контекстная реклама - это эффективный инструмент в интернет маркетинге, целью которого является увеличение продаж. Главный плюс контекстной рекламы заключается в том, что она работает избирательно.